Med-Tech Marketing Funnel
January 2026
MedTech Company & Contact Intelligence Pipeline
I designed and built an end-to-end data pipeline to identify, enrich, and continuously monitor high-fit U.S. MedTech companies, innovators, and decision-makers in advanced surgical devices and robotics.
Problem
An EU MedTech startup focused on commercializing complex surgical robotics lacked a reliable, current view of ICP-qualified U.S. companies and technical innovators. Existing data was outdated and unsuitable for prioritized outreach or market analysis. I was provided a clear Ideal Customer Profile (ICP), and potential data sources.
Solution
I built a repeatable, automated intelligence pipeline that transforms semi-structured sources into a clean, deduplicated, and prioritized ICP database.
Process
Research
- Smoke tested given potential data sources and researched new ones.
- There are a lot of high-fee subscription aggregated data repositories in this space, but this was a low-budget project and none of the sources was in my budget nor exactly what I wanted. I had a discovery meeting with highest potential aggregate data source salesperson, still not exactly what we needed.
- I found alternative civic data sources that gave clearer, more reliable data for the initial signal.
Data Sources
I integrated three primary data sources: patent filings (Lens.org), FDA 510(k) submissions, and SEC Form D funding disclosures. Each required translating qualitative ICP criteria into structured regulatory codes for filtering, along with source-specific ETL pipelines. I first prototyped extraction logic in Python, then operationalized the workflows in n8n, deployed locally in a Docker container for reproducible automation.
Patents
Patent data was obtained from lens.org and filtered using CPC codes (Central Product Classification), focused on products and services. This was my most granular filter and the strongest signal because it pinpoints very specific technologies.
I prototyped the data extraction in python from downloaded zip file, so I could explore data and fine tune the process.
I then replicated this process in n8n and used an HTTP call to the website for quarters. Initially, I looped through each quarter for several years to establish a base, then set it up for quarterly update.
LLM Filtering
To further filter patents to the ICP, I built an LLM classifier to resolve ambiguous technical cases. This is a high level diagram:
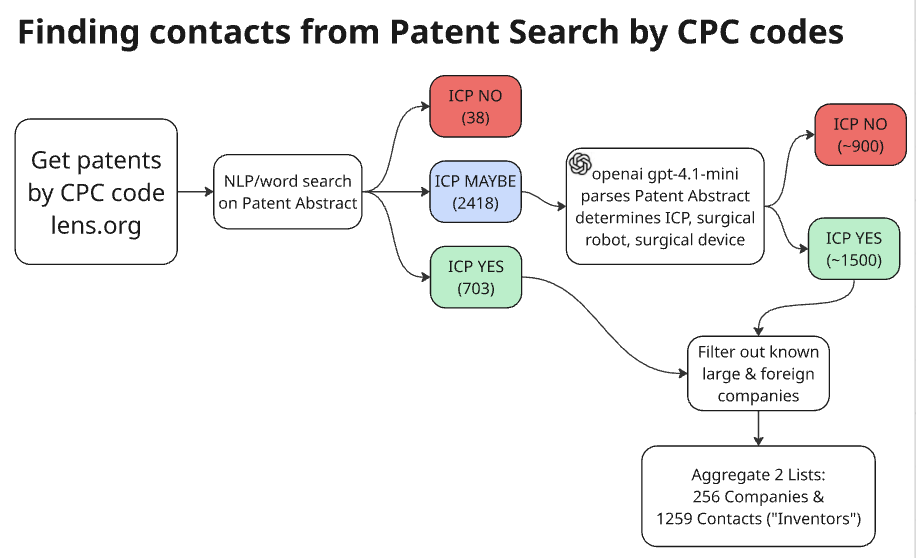
I used Patent Abstracts, which gave a very detailed description of the specific technologies used. I used NLP to patent abstracts for first-pass ICP classification (Yes / No / Maybe)
Then I instructed an LLM (openai gpt-4.1 mini) on how to specifically classify ICP (Yes/No). I tested various models using the same limited abstracts; 4.1 mini was a clear winner, best with niche technical detail. I fed the Maybe bin through the classifier and got 1500 patents. I filtered out known large companies that did not fit ICP size limits, then aggregated the data to create organization and contacts lists.
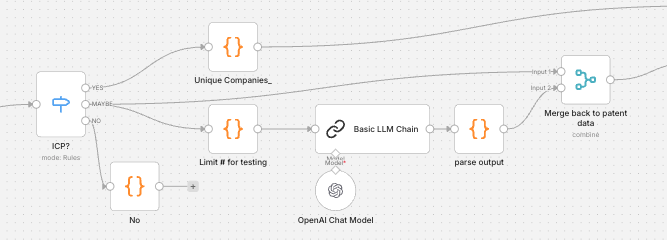
This is the n8n workflow LLM Patent Classifier
FDA 510(k)
Product codes are derived by industry code and specific type of product. They are less granular than patent data. This proved to be less useful because these products later in development stages and I wanted to capture very early research.
SEC Form D
SEC Funding data is classified by Industry group type. This gives us public funding data that is then matched with specific company names to enrich data with funding history.
Python Code Data Extraction
from pathlib import Path
import pandas as pd
import re
BASE_DIR = Path("2025Q4_d") # updated quarterly
read in folder
dfs = for tsv_path in BASE_DIR.glob("*.tsv"): name = tsv_path.stem dfs[name] = pd.read_csv(tsv_path, sep="\t", dtype=str, encoding="utf-8")
separate out into files (only using ISSUERS and OFFERINGS)
issuers = dfs["ISSUERS"] offering = dfs["OFFERING"] #submission = dfs["FORMDSUBMISSION"] #recipients = dfs["RECIPIENTS"] #related = dfs["RELATEDPERSONS"] #signatures = dfs["SIGNATURES"]
join issuers + offering so we can filter by industry
iss = issuers.copy() off = offering[["ACCESSIONNUMBER","INDUSTRYGROUPTYPE","TOTALAMOUNTSOLD","TOTALOFFERINGAMOUNT","SALE_DATE","YETTOOCCUR"]].copy() base = iss.merge(off, on="ACCESSIONNUMBER", how="left")
df = base[ base["INDUSTRYGROUPTYPE"] .astype(str) .str.strip() .eq("Other Health Care") ].copy() #df.head()

Data Aggregation & Expantion
I aggregated the patents by companyImplemented fuzzy matching and consolidation logic to aggregate patents to produce organization list.
- Exploded out contancts from the inventors field to populate contacts list, including their history of patent research.
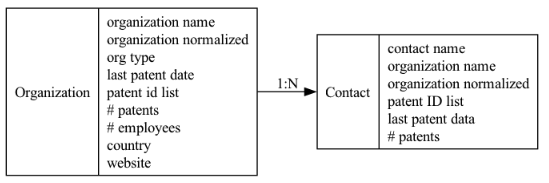
Data Enrichment
Enriched data using AI model-ensembling. (cross-validation between different models) I used openai and claude, to get HQ country, verified website, company size.
Value Created
I delivered high-signal ICP dataset of companies and contacts (diagram below) for the marketing team.
- Significantly expanded U.S. company and contact coverage
- Reduced manual research and data cleanup effort through automation
- Built an extensible LLM ICP classifier to ingest and classify records from large text fields
- Created repeatable automated ETL and data aggregation workflows in n8n